ディープランニング(深層学習)は、大きく分けて3つの種類があります。①答え(教師データ)を決めて行う学習、②答え(教師データ)を決めないで行う学習、③強化学習(自ら答えを作り出す学習)
1回目と2回目は、①答え(教師データ)を決めて行う学習の仕組みについて取り上げます。この学習の仕組みは、「回帰分析・分類分析」の2つの分析手法を使用して行われています。
2回目は分類分析を利用した広く産業界で普及しようとしている故障検知・予測などの手法を、簡単な例を挙げて紹介したいと思います。
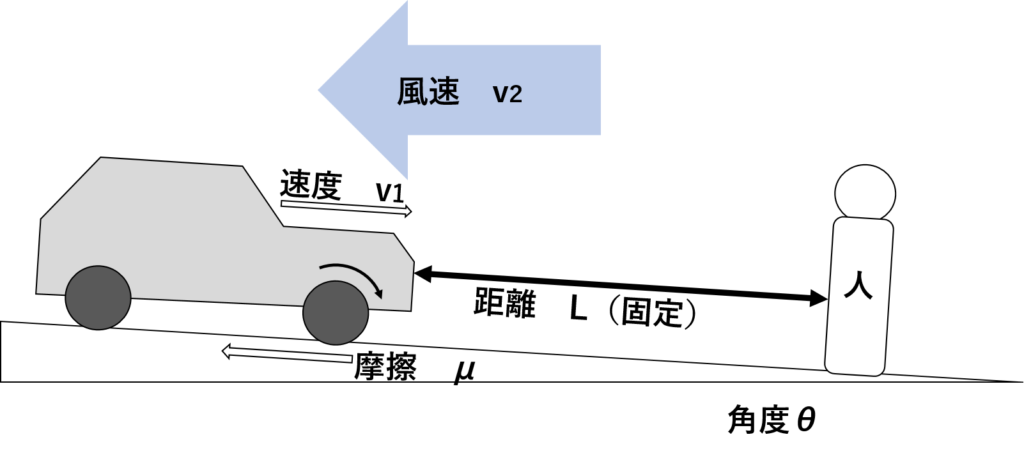
以下のように自動車が人を検知した距離で、走行中から停止する際に、その時の測定値(速度、摩擦、角度、風速)から人への衝突防止ができるかどうか、自動車に判断させたいとしたいとします。
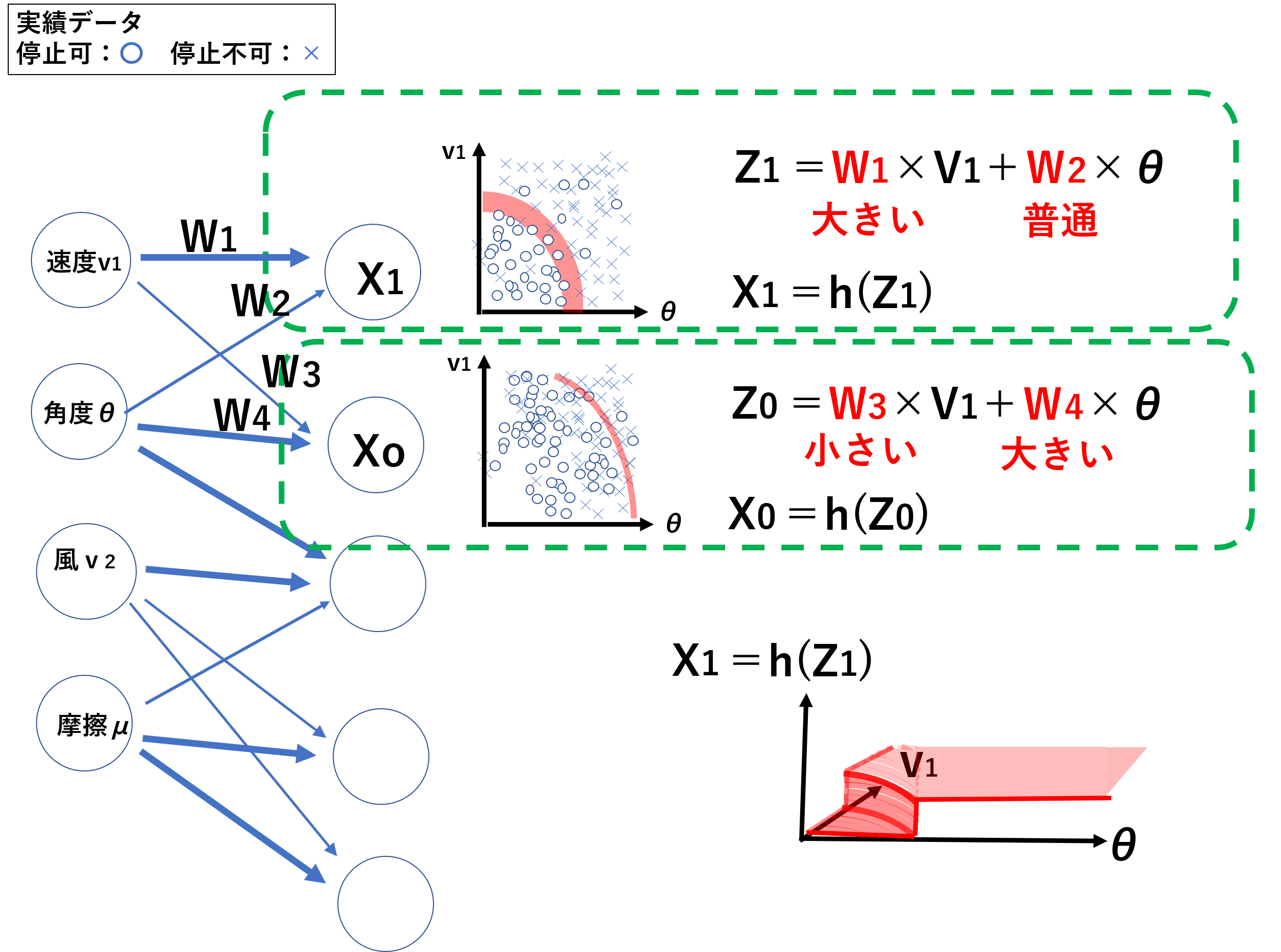
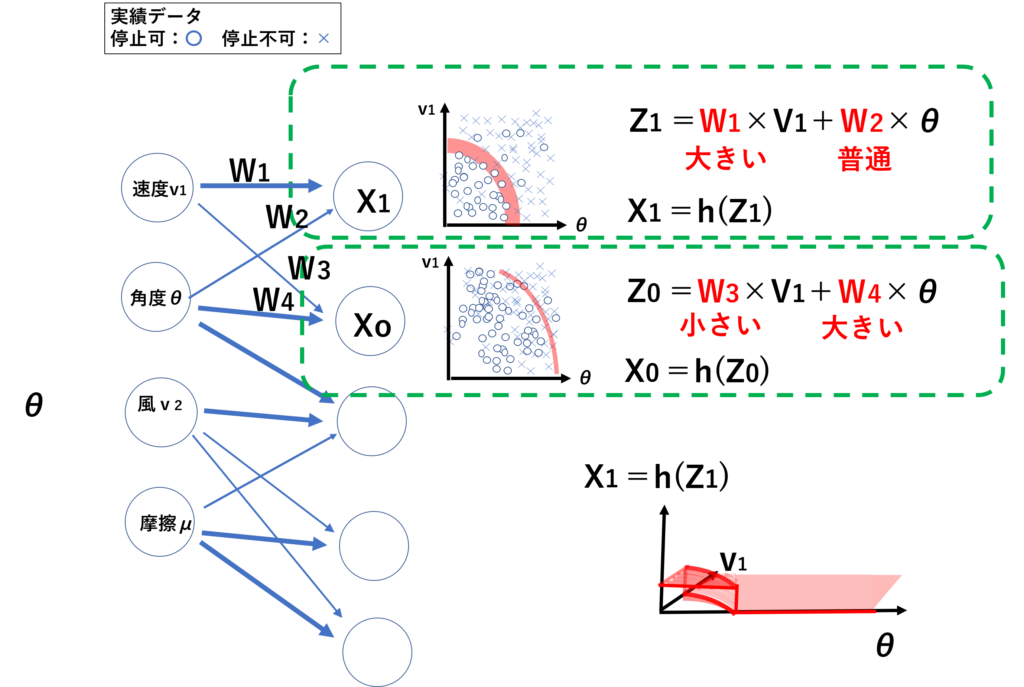
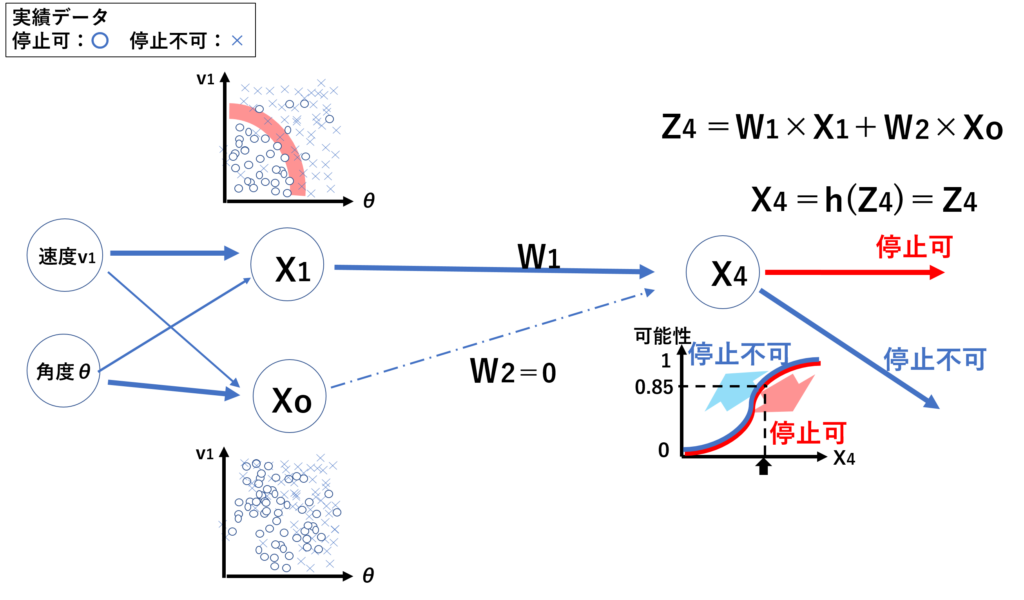
実績の停止できた時のデータとできなかったデータを、答え(教師データ)として、ディープラーニングに読み込ませます。ディープラーニングでは、各測定パラメータ(速度、角度等)の単位認識ができず、一番影響する各パラメータもわからないため、各パラメータの影響度(重み:W)を変えて、多くの種類の分布を比較します(ここでは説明しやすいように速度と角度にみ表示しています)。そして、各分布グラフで、停止可(停止できた:〇)と停止不可(停止できなかった:×)の実績データの境界線を見つけ出します。その境界線を基準として各パラメータが境界線を越えたとき、停止の可否を出力します。
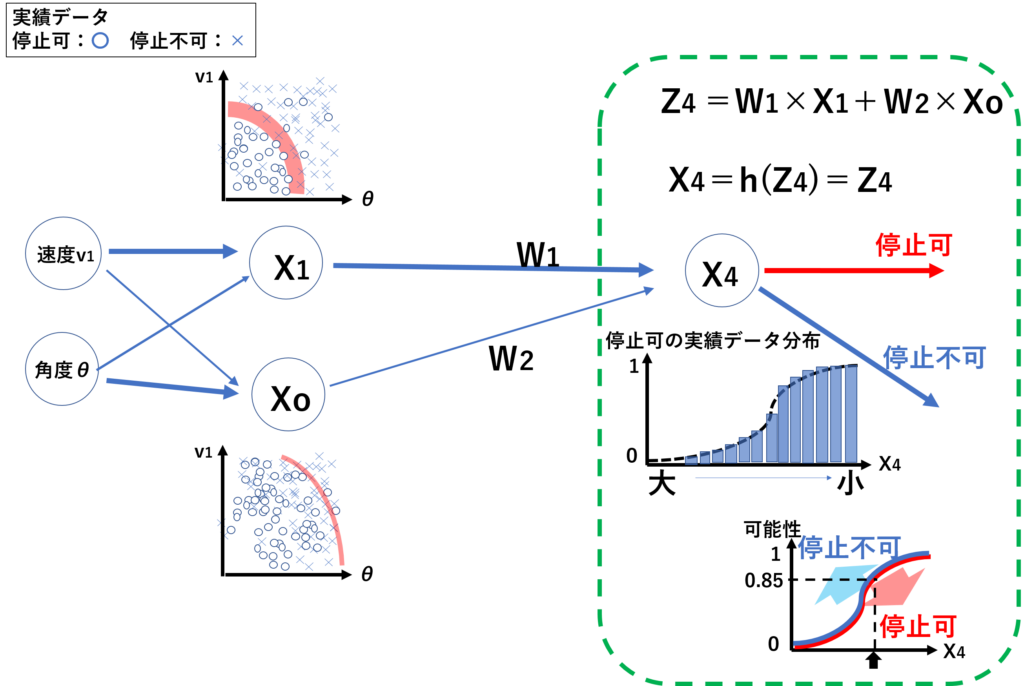
見つけ出した各境界線に基づき、停止可(停止できた:〇)のデータX1とX0からX4を算出します。
予測されたデータX4を別の教師データと比較したとき、停止可(停止できた:〇)と予測されたX4のデータが、教師データの停止可(停止できた:〇)と、どれだけ結果が一致しているか確立で分布化させます(停止不可データについても同様に一致確立を分布化)。この分布を基に、答えの予測値で停止可と判断されたデータの停止できる確率を割り出す近似グラフ(ロジスティック関数)を作成し、答えを確立として出力します。
実績データを読み込ませて学習させてゆくうちに、W2の値を0にして、X0の影響の結果をなくす方が正確であると確率分布から判断されます。(W2が小さくなってゆく仕組みは勾配降下法とういう仕組みを使っています。この仕組みについては3回目で紹介します。)
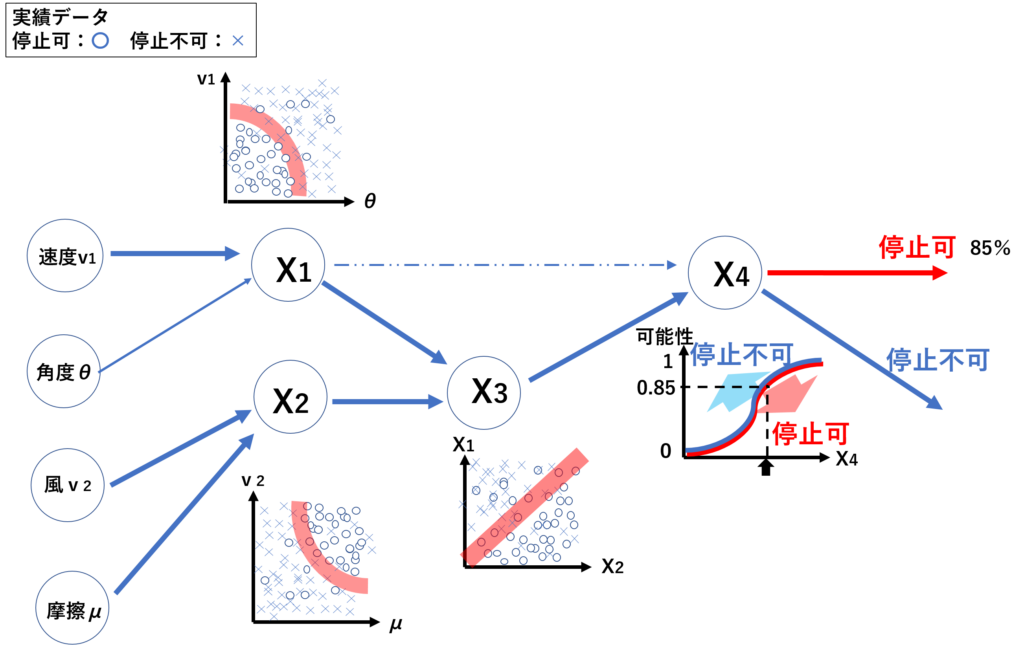
実績データをさらに読み込ませ学習させてゆくうちに風と摩擦(路面凍結)の影響を加味した方が判定の精度が上がることにたどり着きます。これが分類分析で隠れ層を見つける仕組みです。

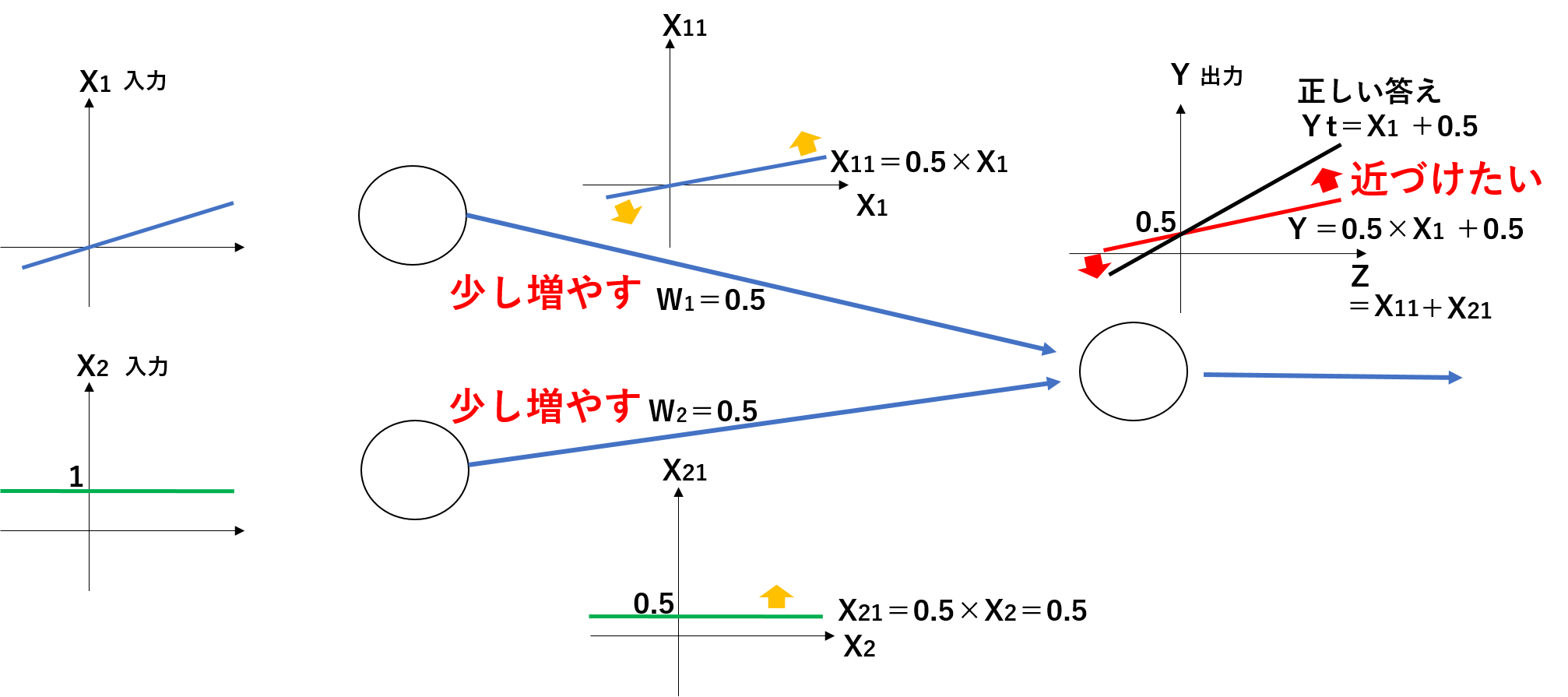
コメント