「畳込みニューラルネットワーク」というディープラーニングの学習手法は、大量のデータ集合体である画像をニューラルネットワークで認識するうえで、コンピュータの演算負荷が大きくかかってしまうため、画像情報をできるだけ少なくして演算を行うための方法です。ここでは、畳込み層とプーリング層で行う画像圧縮処理の手法について説明します。
以下二つの画像が同じ人の顔であることを学習させる例を用いて説明します。

本来画像すべてを対象に行いますが、ここでは説明のため、以下のように各画像の口の部分を切り取った部分についての処理を考えます。

ディープラーニングでは色を数値化しなければ処理できないため、黒いマスは1、白いマスは-1に置き換えます。(カラーの場合、赤のみの画像、青のみの画像、黄色のみの画像として同じように濃度に合わせ1~-1などの範囲で数値化されます。また、特徴の大きいところと小さいところで数値の差を出すことで、特徴の抽出がより正確になるため、学習写真を数値化する際、各マスに対し、カーネルと呼ばれる係数を掛け合わせられて数値化されます。このカーネルの係数は、学習写真を覚えさせる過程で行われる分類学習の際、誤差伝搬法によって求めらるニューラルネットワークの重みになります。)

この二つの画像で同じ場所の数字をかけ合わせる作業を行います、そうすると、以下のように一致しているところは1(=1×1または-1×-1)と大きな数字になり、不一致の場所は-1と小さな数字になります。(実際は同じ場所が比較すべき場所とは限らないため、学習写真側のある区間で区切った範囲を、1マスずつずらしながら計算し以下の表を大量に作成してゆきます。今回は簡略化し、すべての比較すべき場所が一致しているものとして、学習写真側を4×4マスに区切って比較したこととします。)

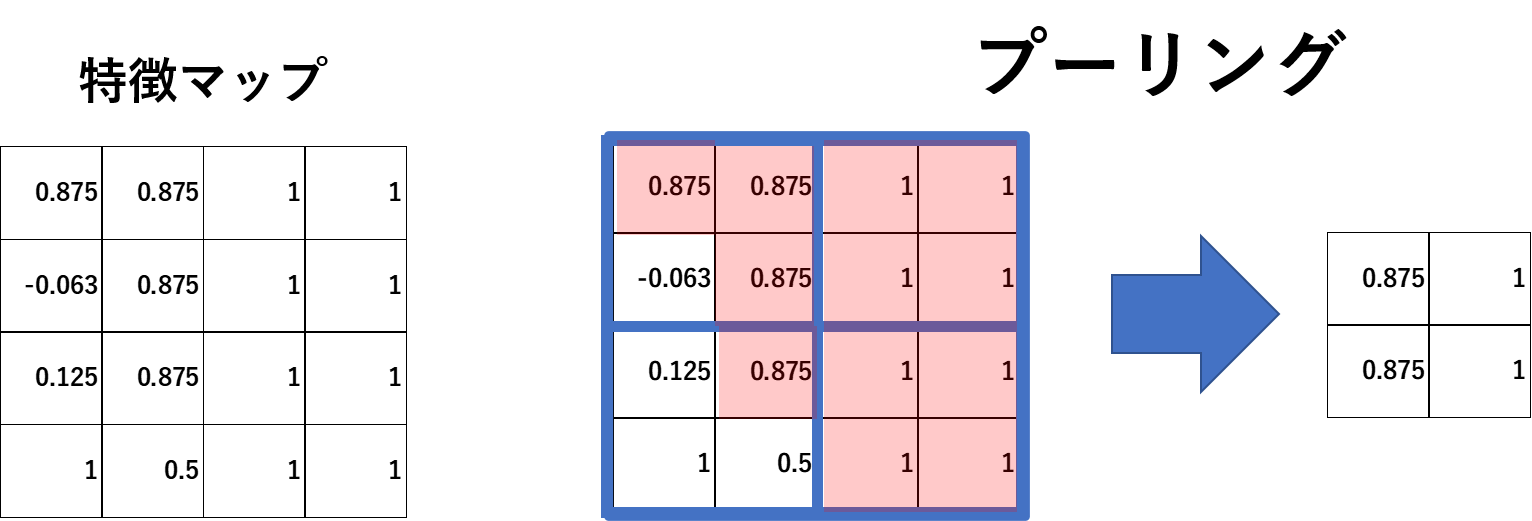
すべての分割した範囲で、数字を合計しマスの数で割って、マップを作ります。これを特徴マップといい、こうすることで、最初の2つの画像で一致しているところは数字が高く、不一致の場所ほど数字が小さくなります。そして、ここまでの作業が畳込み層で行われる畳込みの処理の方法です。

ほとんどの画像の場合、特徴マップは、上記のように4×4マスなどと小さなマップにはならないため、ここからさらにデータを圧縮する目的で、以下のように4つのマスで最も大きい数値を代表として取り出し、2×2のマップにします。これがプーリング層で行われる処理です。
一般的には、画像はデータ数が多いため、ここまでの畳込みとプーリングの処理を以下の図のように何度も繰り返し行い、特徴だけ残しながらデータの圧縮を行っていきます。

ここではデータが十分少なくなったので先ほどの特徴マップとしますが、圧縮を終えたデータは、以下のように1マスごとの数値がニューラルネットワークの数値として入力されてゆきます。ここからは、第二回で説明したディープラーニングの分類学習の方法によって行われる形となります。

コメント